Cascading Failure: Deconstructing the October 2025 AWS Outage and Its Systemic Lessons
A deep technical analysis of the October 20, 2025 AWS outage, revealing how a localized DNS failure cascaded globally due to systemic architectural vulnerabilities and highlighting critical lessons for building resilient cloud infrastructure.
Executive Summary
On October 20, 2025, a significant portion of the global internet experienced a widespread service disruption originating from within Amazon Web Services (AWS), the world's largest cloud computing provider. The event, which lasted for several hours, impacted a vast and diverse array of digital services, including social media, financial platforms, gaming, enterprise software, and government functions. This report provides a rigorous, evidence-based analysis of the incident, its technical root cause, the mechanics of its propagation, and the systemic vulnerabilities it exposed within modern hyperscale cloud infrastructure.
The investigation concludes that the outage was initiated by a highly specific and localized technical fault: a Domain Name System (DNS) resolution failure affecting the Amazon DynamoDB service endpoint in the US-EAST-1 (Northern Virginia) region. This was not a failure of the core database service itself, but of the mechanism used by other applications and services to locate it. The data within DynamoDB remained secure, but for several hours, it was unreachable, as if a critical entry in the internet's address book had been temporarily erased.
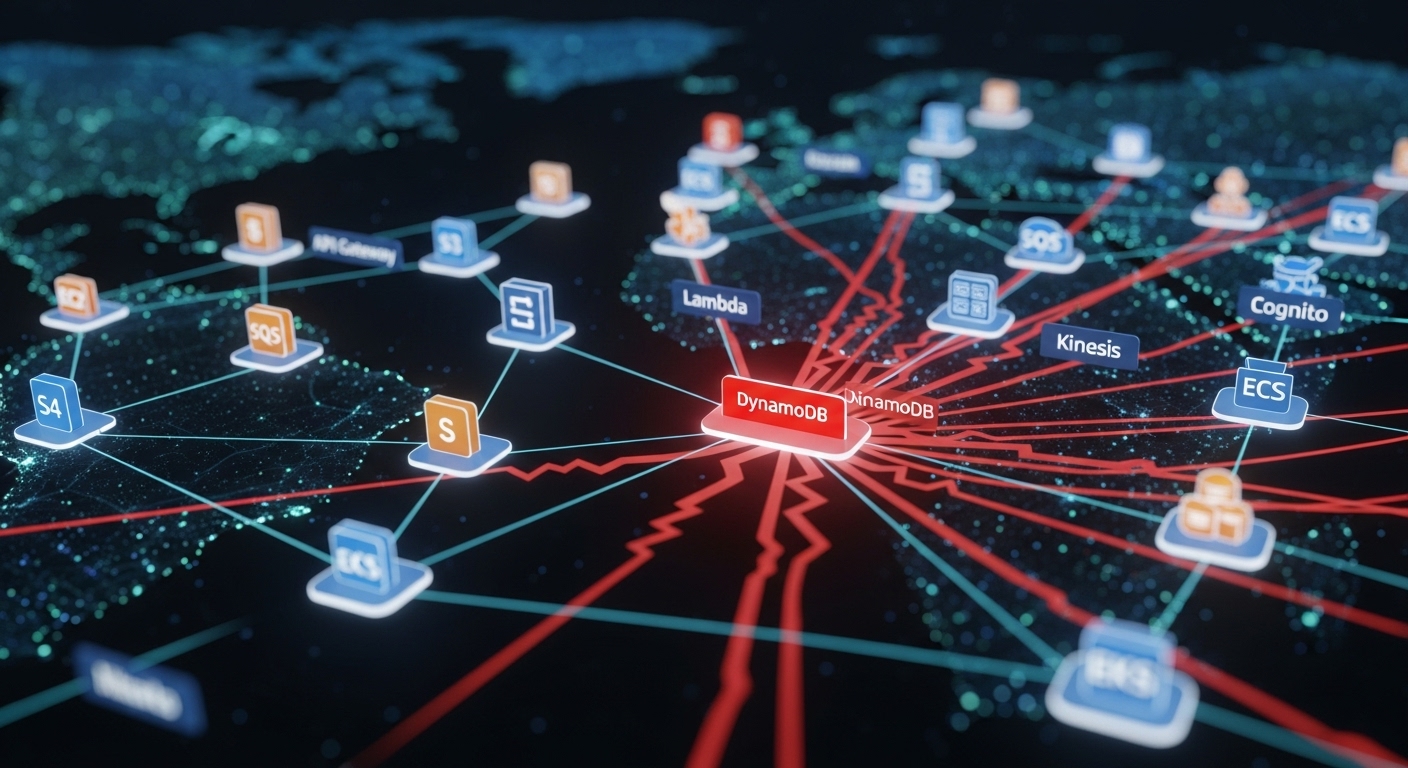
The analysis demonstrates that the global impact of this outage was vastly disproportionate to the localized nature of the initial fault. This amplification was the result of a cascading failure, propagated through a complex and tightly-coupled web of service inter-dependencies. The failure of DynamoDB, a foundational service, triggered failures in dozens of other AWS services that rely upon it for their own core functions, including compute, identity management, and serverless execution.
Furthermore, this report establishes that the incident was not a random, unpredictable event, but rather the manifestation of latent architectural risks. A central finding is the critical dependency of numerous AWS services, including the control planes of "global" services like AWS Identity and Access Management (IAM) and Amazon Route 53, on the US-EAST-1 region. This architectural "center of gravity," a legacy of US-EAST-1 being the original AWS region, creates a single point of failure for certain administrative operations that has global impact. This event, along with a pattern of similar historical outages originating in US-EAST-1, reveals a structural vulnerability that contradicts the simplified model of complete regional independence.
A critical second-order failure was also identified: the impairment of AWS's own monitoring, support, and public communication systems. These tools, being dependent on the very infrastructure they are designed to monitor, were compromised by the outage, delaying diagnosis, remediation, and transparent communication.
This report concludes with a series of findings and actionable recommendations for cloud architects, operators, and the broader technology industry. It advocates for the adoption of architectural principles such as static stability, aggressive fault isolation, and the decoupling of critical dependencies from the US-EAST-1 region. For the industry at large, the event underscores the urgent need for greater architectural transparency from cloud providers and strategic investment in multi-region and multi-cloud resilience to mitigate the systemic risks of cloud concentration.
Section 1: Anatomy of the Outage
This section establishes a factual, evidence-based narrative of the event, from its inception to its resolution. It meticulously reconstructs the timeline and details the breadth of the impact on the global digital economy.
1.1 The Initial Anomaly: Onset and Early Indicators
The service disruption of October 20, 2025, began without warning at approximately 12:11 AM Pacific Daylight Time (PDT), which corresponds to 3:11 AM Eastern Time (ET) and 8:11 AM British Summer Time (BST). The first public signs of a large-scale problem emerged not from an official announcement, but from a massive, correlated surge of user-submitted error reports on third-party outage tracking platforms like Downdetector. Users across the globe simultaneously began reporting that dozens of popular and seemingly unrelated applications, websites, and services were inaccessible or malfunctioning.
Amazon's initial public acknowledgment of the issue appeared on its AWS Service Health Dashboard. The first updates were characteristically cautious, citing an investigation into "increased error rates and latencies for multiple AWS services in the US-EAST-1 Region". This region, located in Northern Virginia, was immediately identified as the epicenter of the event. This initial communication, while confirming a problem, lacked specific details about the root cause, a standard practice in the early phases of a major incident response while engineers work to diagnose the fault.
Although the identified source of the issue was geographically located on the U.S. East Coast, the impact was instantaneously global. The nature of the affected services—foundational components upon which global applications are built—ensured that the ripple effect would not be constrained by geography, immediately transforming a regional fault into a worldwide digital disruption.
1.2 The Cascade: Propagation of Failure Across the AWS Ecosystem
The ambiguity of the initial reports began to resolve approximately one hour and fifteen minutes into the event. At 1:26 AM PDT (9:26 AM BST), AWS provided a critical update, narrowing the scope of the investigation to "significant error rates for requests made to the DynamoDB endpoint in the US-EAST-1 Region". This announcement was the first definitive indication of the outage's origin point: a failure related to Amazon DynamoDB, a foundational, fully managed NoSQL database service used extensively by both external customers and internal AWS services.
The degradation of DynamoDB in US-EAST-1 acted as the trigger for a classic cascading failure. A cascading failure occurs when the failure of a single component in a distributed system increases the load or stress on dependent components, causing them to fail in turn, creating a chain reaction. In this instance, the inability to reliably communicate with the DynamoDB service endpoint rendered a vast number of dependent services inoperable.
The blast radius of the DynamoDB issue quickly expanded to encompass a significant portion of the AWS service portfolio. Amazon's own status page eventually confirmed that at least 37 distinct AWS services were directly impacted by the incident. This list included fundamental building blocks of the cloud, such as:
- Identity:
AWS Identity and Access Management (IAM) - Compute:
Amazon Elastic Compute Cloud (EC2) - Serverless:
AWS Lambda - Networking:
Amazon CloudFront,AWS Global Accelerator - Queuing and Messaging:
Amazon Simple Queue Service (SQS),Amazon MQ - Monitoring:
Amazon CloudWatch
The failure propagated logically through the service stack. Applications running on EC2 or Lambda that required access to DynamoDB for data storage or state management began to fail. Services that used DynamoDB internally for their own operations, such as IAM, also became impaired. This rapid, cross-service degradation demonstrated the tight coupling and deep, often opaque, inter-dependencies that exist within a hyperscale cloud environment.
| Timestamp (UTC) | Timestamp (PDT/BST) | Event Description | Key Services Affected | Source(s) |
|---|---|---|---|---|
| 07:11 | 12:11 AM / 8:11 AM | AWS reports first experiencing outages; Downdetector reports begin to spike. | AWS, Snapchat, Venmo, Ring, Fortnite, Pokémon GO | |
| 07:40 | 12:40 AM / 8:40 AM | Widespread disruptions reported across dozens of websites and apps. | Roblox, Duolingo, Canva, Lloyds Bank | |
| 08:26 | 1:26 AM / 9:26 AM | AWS confirms "significant error rates" for the DynamoDB endpoint in US-EAST-1. | DynamoDB, other dependent AWS services | |
| 09:01 | 2:01 AM / 10:01 AM | AWS identifies a potential root cause related to DNS resolution of the DynamoDB endpoint. | DynamoDB, IAM, Support Center | |
| 09:22 | 2:22 AM / 10:22 AM | AWS deploys an initial fix for the DNS issue. | N/A (Mitigation Action) | |
| 09:27 | 2:27 AM / 10:27 AM | AWS reports "early signs of recovery" but warns of latency and a backlog of requests. | General recovery begins for some services. | |
| 09:34 | 2:34 AM / 10:34 AM | A secondary, large spike in outage reports for Reddit is observed. | ||
| 10:00 | 3:00 AM / 11:00 AM | Many gaming services, including Roblox and Fortnite, report a return to normal operations. | Roblox, Fortnite, Epic Games Store | |
| 10:05 | 3:05 AM / 11:05 AM | Payment processor Square reports its services are back online. | Square | |
| 10:27 | 3:27 AM / 11:27 AM | AWS reports "significant signs of recovery" with most requests succeeding. | Most AWS services | |
| 11:08 | 4:08 AM / 12:08 PM | AWS provides an update on lingering issues, including EC2 launch errors and Lambda polling delays. | EC2, Lambda | |
| 12:00 | 5:00 AM / 1:00 PM | AWS states it will provide a further update on full recovery for remaining EC2 and Lambda issues. | EC2, Lambda |
1.3 The Global Impact: A Digital Economy Disrupted
The concentration of failures within AWS's foundational services resulted in a widespread disruption of the digital economy. The phrase "half the internet" was used by some observers to describe the scale of the impact, reflecting the deep integration of AWS into the fabric of modern online life. The outage affected a broad and diverse range of sectors, demonstrating that few corners of the digital world are isolated from the health of the major cloud providers.
Key Affected Sectors and Services:
- Social Media and Communication: Popular platforms including Snapchat, Reddit, Signal, and Slack experienced significant downtime or degraded performance. Users were unable to send messages, load content, or log in.
- Gaming and Entertainment: The outage crippled major online gaming platforms like Fortnite, Roblox, and Pokémon GO, as well as the PlayStation Network. Millions of players were unable to log in or access online features. Streaming services, including Disney+, also reported disruptions.
- Financial Technology and Banking: The financial sector was heavily impacted. Cryptocurrency exchanges like Coinbase, trading apps like Robinhood, and payment services like Venmo and Square all reported service interruptions. The outage also affected traditional banking, with major UK institutions such as Lloyds Bank, Halifax, and Bank of Scotland experiencing issues with their online and mobile banking applications.
- Aviation and Transportation: Major U.S. airlines, including Delta Air Lines and United Airlines, reported disruptions to their websites and mobile apps. Passengers encountered difficulties with checking in, viewing reservations, and managing their travel during the outage.
- Government Services: The incident's reach extended into the public sector. The United Kingdom's tax and customs agency, HM Revenue and Customs (HMRC), was among the government services affected, with users unable to access its website.
- Productivity and Enterprise Software: Widely used business and consumer applications such as Canva, Duolingo, Zoom, and Asana suffered from the outage, disrupting workflows for countless individuals and organizations.
- Amazon's Own Ecosystem: The outage notably impacted Amazon's own consumer-facing products and services. The primary Amazon e-commerce website, the Prime Video streaming service, the Alexa voice assistant, and Ring smart home security devices all experienced degraded functionality, from failed voice commands to inaccessible video feeds.
The impact was not binary; many services experienced a "degraded" state rather than a complete shutdown. Users reported a variety of issues, such as being able to stream video but not log in, or experiencing significant lag and intermittent failures. This pattern is characteristic of failures in complex distributed systems, where different subsystems may be in varying states of health and recovery, leading to an inconsistent and frustrating user experience.
1.4 The Response and Recovery: Mitigation Efforts and Service Restoration
AWS's incident response teams began diagnostic and mitigation efforts immediately upon detection of the anomaly. At 2:01 AM PDT, the company publicly announced that its engineers had identified a "potential root cause" connected to the DNS resolution of the DynamoDB API endpoint. The statement also noted that they were pursuing "multiple parallel paths to accelerate recovery," a standard incident management strategy for complex failures where multiple potential solutions are attempted simultaneously to reduce the time to mitigation.
The first significant mitigation step was deployed at 2:22 AM PDT. Shortly thereafter, AWS reported "early signs of recovery," but correctly cautioned that the system would remain unstable for some time due to "additional latency" and a "big backlog of queued requests" that had accumulated during the period of unavailability. This backlog represents a common challenge in large-scale system recovery, where a "thundering herd" of retrying clients can overwhelm a service as it comes back online, requiring careful throttling and management to prevent a relapse.
The recovery process was staggered and non-uniform across the affected services. Some platforms, such as the payment processor Square and the popular game Wordle, were reported to be back online relatively quickly, by approximately 3:05 AM PDT. However, other major services exhibited more complex recovery dynamics. Reddit, in particular, experienced a secondary, massive spike in outage reports after the initial AWS fix was deployed. This secondary failure was likely due to lingering issues in the services upon which Reddit depends, such as AWS Lambda and AWS CloudTrail, which were still working through their own backlogs of events.
By 5:27 AM ET (2:27 AM PDT), AWS issued a more confident update, stating that they were observing "significant signs of recovery" and that "most requests should now be succeeding". Despite this progress, the incident was not fully resolved. AWS continued to report ongoing work to clear remaining issues, specifically "EC2 launch errors" and "elevated polling delays for Lambda," indicating that the compute and serverless layers of the platform were the last to fully stabilize. Full recovery for all services and the complete processing of all backlogged tasks continued for several more hours, with the incident's primary effects lasting for the better part of the business morning in Europe and the early morning in North America.
Section 2: Technical Root Cause Analysis: The DNS Failure Chain
This section performs a deep technical dive into the proximate cause of the outage. It will deconstruct the specific failure mechanism and analyze the underlying AWS architectural components and design decisions that contributed to the event.
2.1 The Point of Failure: DNS Resolution for the DynamoDB API Endpoint
The direct trigger for the October 20, 2025 outage was a failure within the Domain Name System (DNS) infrastructure responsible for resolving the Application Programming Interface (API) endpoint for Amazon DynamoDB in the US-EAST-1 region. DNS is the foundational directory service of the internet, responsible for translating human-readable domain names (e.g., dynamodb.us-east-1.amazonaws.com) into the numerical Internet Protocol (IP) addresses that computers use to locate one another. A failure in this system is akin to a phonebook losing the number for a critical service; the service may be running perfectly, but no one can call it.
Crucially, AWS's internal analysis indicated that this was not a failure of the DynamoDB service's data plane. The databases themselves continued to operate, and the data stored within them was not compromised. The failure was confined to the discovery and routing layer. As one expert analyst described the effect, it was as if "large portions of the Internet suffered temporary amnesia"; the data was safely stored, but for several hours, client applications and other services could not find it.
This failure manifested to users and dependent services as a sharp increase in "error rates and latencies". When a client application (or another AWS service) attempted to make an API call to DynamoDB, its initial step—resolving the service's DNS name—would fail or time out. This prevented the establishment of a network connection, leading to application-level errors. The widespread dependency on DynamoDB meant that this single point of failure in the DNS resolution path had a massive and immediate downstream impact.
2.2 Architectural Analysis of AWS DNS and Endpoint Resolution
To understand the specific nature of this failure, it is necessary to examine the architecture of DNS and service endpoint resolution within AWS. This is not a monolithic system but a collection of services and features designed to handle different use cases, from public internet traffic to private, isolated networks.
Amazon Route 53 Architecture
Amazon Route 53 is AWS's global, highly available DNS service. It is architected for extreme resilience, with a key design principle being the separation of its control plane and data plane.
- The data plane is responsible for the core function of answering DNS queries. It is a globally distributed system, running across more than 200 Points of Presence (PoPs), and is designed for a 100% availability Service Level Agreement (SLA). Its distributed nature ensures that a failure in one location does not impact query resolution elsewhere.
- The control plane provides the administrative APIs used to create, update, and delete DNS records (e.g., in the AWS Management Console or via API calls). To ensure strong consistency and durability for these management operations, the control plane for Route 53 is centralized in the
US-EAST-1region.
The October 20th outage was not a failure of the global Route 53 data plane. A failure of that magnitude would have had even more catastrophic and widespread consequences. Instead, the issue was localized to a more specialized subsystem responsible for resolving service endpoints within the AWS network itself.
VPC Endpoints for Private Service Access
Within an AWS Virtual Private Cloud (VPC), customers can access AWS services without sending traffic over the public internet by using VPC Endpoints. This is a critical feature for security and network performance. Historically, AWS has provided two primary types of VPC Endpoints:
- Gateway Endpoints: An older design available only for
Amazon S3andAmazon DynamoDB. A Gateway Endpoint modifies the route table of a VPC subnet to direct traffic destined for the service's public IP range to a private network path within AWS. - Interface Endpoints: A more modern design powered by AWS PrivateLink, available for most AWS services. An Interface Endpoint provisions an Elastic Network Interface (ENI) with a private IP address directly within the customer's VPC. Traffic to the service is directed to this local IP address.
The Critical Architectural Deviation: DynamoDB Interface Endpoints
While Gateway Endpoints for DynamoDB have been available for years, AWS more recently introduced support for Interface Endpoints for DynamoDB, providing customers with more granular security controls (e.g., Security Groups) and connectivity options from on-premises networks. However, this implementation came with a critical architectural nuance that distinguishes it from almost all other AWS services.
DynamoDB Interface Endpoints do not support the "Private DNS" feature. When Private DNS is enabled for a standard Interface Endpoint (e.g., for EC2 or SQS), AWS automatically manages the DNS resolution within the VPC. Queries for the standard public service hostname (e.g., sqs.us-east-1.amazonaws.com) are transparently resolved to the private IP address of the Interface Endpoint's ENI. This allows application code to remain unchanged whether it is accessing the service publicly or privately.
Because this feature is absent for DynamoDB Interface Endpoints, the standard public hostname (dynamodb.us-east-1.amazonaws.com) cannot be resolved from within an isolated subnet that only has an Interface Endpoint. Instead, AWS generates a set of unique, endpoint-specific DNS names (e.g., vpce-1a2b3c4d-5e6f.dynamodb.us-east-1.vpce.amazonaws.com). Applications and services that wish to use this private path must be explicitly configured with this special endpoint URL.
This non-standard behavior created a distinct, specialized DNS resolution path for DynamoDB Interface Endpoints, separate from the general-purpose Route 53 data plane and the standard Private DNS mechanism. It was the failure of this specific, specialized system that triggered the outage.
| Endpoint Type | Service Example | Private DNS Support | Resolution Mechanism | Client Code Impact |
|---|---|---|---|---|
| Gateway | Amazon S3, Amazon DynamoDB | N/A | Modifies VPC route table with a prefix-list to redirect traffic to the service's public IP range over a private path. | None. Client uses standard public endpoint name. |
| Interface | Amazon EC2, Amazon SQS, AWS Lambda | Yes (Standard) | Provisions an ENI with a private IP. A private hosted zone within the VPC resolves the standard public endpoint name to this private IP. | None. Client uses standard public endpoint name. |
| Interface | Amazon DynamoDB | No | Provisions an ENI with a private IP. Generates unique, endpoint-specific DNS names that resolve to the private IP. | Required. Client must be explicitly configured to use the endpoint-specific URL. |
2.3 Contributing Factors: Latent Vulnerabilities in Large-Scale DNS Systems
While the specific bug or configuration error that caused the DNS resolution failure for the DynamoDB endpoint has not been publicly detailed by AWS, the incident aligns with known failure modes of large-scale, complex DNS infrastructure. Such systems, even when designed for high availability, are susceptible to several classes of vulnerabilities.
The October 20th event was characterized by AWS and external experts as an internal IT issue rather than a malicious cyber-attack. This points toward one of the following likely contributing factors:
- Configuration Errors: A significant percentage of DNS outages are caused by human error during configuration changes. An incorrect value, a typographical error in a record, or a flawed deployment of a new configuration can have immediate and widespread consequences. Given the complexity of the specialized DNS system for
DynamoDBendpoints, a misconfiguration pushed as part of a routine update is a plausible scenario. - Latent Software Bugs: Complex software inevitably contains bugs. A latent bug can lie dormant for years until a specific set of conditions—such as a particular type of query, an unusual traffic pattern, or a system scaling beyond a previously untested threshold—triggers it. This pattern has been the root cause of previous major AWS outages, such as the Kinesis event of November 2020 and the Lambda event of June 2023, both of which were triggered by scaling activities.
- Resource Exhaustion: DNS servers, like any server, have finite resources (CPU, memory, network connections, file descriptors). A sudden spike in queries or a bug causing a resource leak could lead to server overload, causing them to become unresponsive.
The failure of a non-standard, service-specific DNS path suggests a higher risk profile compared to more mature, general-purpose systems. Architectural choices that deviate from established, battle-hardened patterns can introduce novel failure modes that may not be as well-understood or as resilient as the core infrastructure. The outage was not a failure of "DNS" in the abstract, but a failure of a specific, bespoke implementation choice within AWS's architecture, highlighting the risks associated with such complexity at scale.
Section 3: Systemic Vulnerabilities: The Role of US-EAST-1 and Service Inter-dependencies
This section elevates the analysis from the proximate cause to the systemic conditions that allowed the failure to have such a devastating impact. It will examine the historical and architectural significance of the US-EAST-1 region and the pattern of cascading failures it has repeatedly enabled.
3.1 The Gravity of US-EAST-1: A Historical and Architectural Analysis
The outsized impact of the October 20th outage cannot be understood without appreciating the unique role that the US-EAST-1 (Northern Virginia) region plays in the global AWS architecture. Launched in August 2006, US-EAST-1 was the first AWS region. This historical primacy has established it as an architectural "center of gravity" for the entire AWS ecosystem.
Over nearly two decades, this has led to several key characteristics:
- Size and Maturity: It is the largest and one of the most mature AWS regions, with the broadest availability of services and the most Availability Zones.
- Default Choice: For many years, it was the default region for new accounts and is often the first to receive new services and features, leading to a high concentration of customer workloads.
- Legacy Dependencies: Due to its age, many of AWS's own internal systems and foundational services were originally built in and for
US-EAST-1. Over time, this has created a deep and often non-obvious web of dependencies that anchor back to this single region, even for services that operate globally.
This concentration of both customer workloads and critical internal infrastructure makes US-EAST-1 systemically important. While AWS operates dozens of other regions designed to be isolated from one another, a significant failure in US-EAST-1 has repeatedly demonstrated the potential for global consequences, a pattern that played out again in this incident.
3.2 The Control Plane Dependency: How Global Services Are Anchored to a Single Region
A fundamental concept in AWS architecture is the separation of the control plane and the data plane for most services.
- The data plane is responsible for the primary, real-time function of a service. For example, the
EC2data plane is the running virtual machine, theS3data plane is the storage and retrieval of objects, and theRoute 53data plane is the answering of DNS queries. Data planes are designed for high availability and are distributed across multiple Availability Zones and regions. - The control plane provides the administrative APIs used to manage resources—creating, reading, updating, deleting, and listing (CRUDL) them. For example, launching a new
EC2instance or creating a newS3bucket are control plane operations. Control planes are complex orchestration systems that prioritize strong consistency and durability over raw availability, which often leads to them being centralized.
For a small but critical set of "global" AWS services, this centralization has a profound implication: their control planes are hosted exclusively in a single AWS region. For foundational services like AWS Identity and Access Management (IAM), Amazon Route 53, and Amazon CloudFront, the control plane is located in US-EAST-1.
This architectural decision creates a critical dependency. During a major impairment of the US-EAST-1 region, the control planes for these global services may become unavailable. While their highly distributed data planes are designed to continue functioning—existing IAM credentials will still authenticate, and existing DNS records will still resolve—any administrative action that requires the control plane will fail, globally. A user in the ap-southeast-2 (Sydney) region would be unable to create a new IAM user or update a Route 53 DNS record because that request must be processed by the control plane in us-east-1.
The October 20th outage demonstrated an even more severe failure mode. The issue was not just an impairment of a control plane, but a failure of a foundational data service (DynamoDB) within US-EAST-1. Because other services' control planes and even some data plane components depend on DynamoDB for their own operation, the failure cascaded upwards, impairing the functionality of services far beyond what a simple control plane outage would entail. This reveals a "soft fate-sharing" model where workloads in theoretically isolated regions remain vulnerable to foundational service failures in US-EAST-1.
3.3 A Pattern of Cascading Failures: Lessons from Historical AWS Incidents
The October 20, 2025, outage is not an anomaly. It is the latest in a series of major service disruptions originating in US-EAST-1 that follow a distressingly similar pattern: a localized trigger event leads to a cascading failure that reveals deep, systemic inter-dependencies. Analysis of past AWS Post-Event Summaries (PES) provides clear evidence of this recurring vulnerability.
| Date | Incident Name | Triggering Event | Proximate Root Cause | Key Dependent Services Impacted | Revealed Systemic Vulnerability |
|---|---|---|---|---|---|
| Feb 28, 2017 | Amazon S3 Disruption | Human error during debugging. | Incorrect command input removed a larger-than-intended set of S3 subsystem servers, requiring a full restart. | EC2, EBS, Lambda, S3 Console, Service Health Dashboard | Dependency of core services and monitoring tools on S3. Slow recovery time of large, scaled-out systems. |
| Nov 25, 2020 | Amazon Kinesis Event | Routine addition of server capacity. | Scaling the Kinesis front-end fleet exceeded a per-server OS thread limit, causing cascading failures in request processing. | Cognito, CloudWatch, Lambda, Auto Scaling, EKS, ECS | Latent bug triggered by scale. Deep, undocumented dependencies of many services on Kinesis for data streaming. |
| Dec 7, 2021 | AWS Network Event | Automated scaling activity on the internal network. | An unexpected behavior in scaling software caused a massive surge of connections, overwhelming core network devices. | EC2, DynamoDB, API Gateway, STS, ECS, Fargate, Route 53 | Congestion collapse on a critical internal network. Dependency of monitoring and support systems on the main network. |
| Jun 13, 2023 | AWS Lambda Event | Routine scaling of the Lambda front-end fleet. | Scaling beyond a previously unreached capacity threshold in a single service "cell" triggered a latent software defect. | STS, AWS Sign-in, EventBridge, EKS, AWS Management Console, Amazon Connect | Latent bug triggered by scale. Failure of a single "cell" to be properly isolated, leading to broader impact. |
These historical events reveal several common threads that are directly relevant to the October 2025 outage:
- Scaling as a Trigger: Three of the four major incidents listed were triggered not by a component failure in a steady state, but by a routine operational activity designed to increase capacity or scale the service. This demonstrates that scaling itself is a high-risk operation in complex systems, as it can push components into untested states and expose latent bugs or resource limits.
- Latent Bugs and Hidden Limits: The root causes consistently involve latent software defects or previously unknown operating system limits (e.g., thread counts) that were only revealed under the stress of a specific event. This highlights the difficulty of comprehensively testing systems of this scale for all possible failure modes.
- Cascading Dependencies on Foundational Services: Each outage began in a single, foundational service (
S3,Kinesis, internal networking,Lambda) and then cascaded to a wide array of dependent services. This shows that services likeCognito,CloudWatch, and theAWS Management Consoleare highly susceptible to failures in their underlying dependencies, creating a broad blast radius from a single-point failure. - The US-EAST-1 Epicenter: All of these globally significant outages originated in
US-EAST-1, reinforcing its status as a region with unique systemic risks due to the concentration of foundational services and control planes.
The pattern is clear and predictive: the architecture of AWS, with its deep service inter-dependencies and the historical gravity of US-EAST-1, makes it susceptible to these large-scale cascading failures. The October 20, 2025 outage was not a new type of failure, but a recurrence of a known, systemic vulnerability.
Section 4: The Blind Spot: Failure of Internal Monitoring and Response Systems
A critical, and often overlooked, aspect of large-scale cloud outages is the second-order failure of the very systems designed to monitor, diagnose, and communicate about the incident. The October 20th outage once again highlighted this dangerous circular dependency, where the tools for incident response are caught within the blast radius of the incident itself, creating a blind spot at the most critical moment.
4.1 The Observer Effect: When Monitoring Systems Depend on the Systems They Monitor
During the initial hours of the outage, customers attempting to seek information or assistance were met with further frustration. The AWS Support Center, the primary channel for customers to report issues and receive technical assistance, was itself impaired. AWS's own status updates confirmed that the ability for customers to "create or update Support Cases" was affected by the ongoing event.
This is a recurring and dangerous anti-pattern in AWS's operational infrastructure. An analysis of previous post-mortems reveals that AWS's critical incident response tooling, including the public-facing Service Health Dashboard (SHD) and internal monitoring systems, has repeatedly been compromised during major outages due to its own dependencies on the core AWS services that were failing.
- February 2017 S3 Outage: The post-mortem explicitly stated that AWS was "unable to update the individual services' status on the AWS Service Health Dashboard (SHD) because of a dependency the SHD administration console has on Amazon S3".
- December 2021 Network Outage: The official summary noted that "networking congestion impaired our Service Health Dashboard tooling from appropriately failing over to our standby region" and that "impairment to our monitoring systems delayed our understanding of this event".
This creates a severe operational vulnerability. At the exact moment when engineers, customers, and the public require accurate and timely information, the primary communication channels are broken. This forces engineering teams to rely on slower, more cumbersome "out-of-band" diagnostic methods, such as manually analyzing raw log files from disparate systems, which significantly increases the Mean Time to Diagnosis (MTTD) and Mean Time to Recovery (MTTR). The inability to use purpose-built dashboards and monitoring tools because they are also down is a critical failure of fault isolation.
4.2 Limits of Observability in Hyperscale Environments
Modern cloud operations rely on the principles of observability, which is the ability to understand the internal state of a system by analyzing its external outputs—primarily metrics, logs, and traces. AWS provides a comprehensive suite of services for this purpose, including Amazon CloudWatch for metrics and logs, and AWS X-Ray for distributed tracing.
However, the sheer scale and dynamism of a hyperscale environment like AWS present fundamental challenges to traditional monitoring and observability.
- Signal-to-Noise Ratio: In a system with millions of components generating telemetry data, identifying the meaningful signal of an impending failure amidst a sea of background noise is exceptionally difficult. A high-cardinality environment, where each metric can have thousands or millions of unique labels (e.g., per-customer, per-instance), can overwhelm traditional monitoring systems.
- Complexity and Inter-dependencies: The intricate web of dependencies between microservices means that a problem in one service can manifest as symptoms in a completely different, downstream service. Tracing the root cause through this complex graph during a live incident is a significant challenge, especially when the tracing and logging infrastructure itself may be degraded.
- The "Unknown Unknowns": Monitoring is effective at tracking known failure modes (e.g., CPU utilization exceeding a threshold). Observability aims to provide the tools to debug "unknown unknowns"—novel failure modes that have never been seen before. However, even with rich data, the cognitive load on engineers during a high-stress, large-scale outage is immense. The problem becomes one of timely and accurate sense-making, which is hampered when the primary tools for visualization and analysis (such as the AWS Management Console or internal dashboards) are also unavailable or slow.
The October 20th outage, likely triggered by a latent bug or misconfiguration, is a prime example of an "unknown unknown" becoming a catastrophic failure. The inability of AWS's monitoring systems to provide clear, immediate insight, coupled with the failure of their communication and support channels, points to a systemic blind spot. The architecture of the incident response systems lacks the necessary isolation and resilience to function reliably during the very events they are designed to handle.
Section 5: Findings and Recommendations for Building Resilient Systems
The analysis of the October 20, 2025, AWS outage yields several critical findings regarding the systemic risks inherent in current hyperscale cloud architectures. These findings inform a set of actionable recommendations for cloud architects, operators, and the broader industry to improve the resilience of digital infrastructure.
5.1 Finding 1: Critical Dependency on Single-Region Control Planes
The architecture of foundational AWS global services, such as IAM and Route 53, concentrates their control plane functions in the US-EAST-1 region. This design choice, made to ensure strong consistency for administrative operations, creates a single point of failure that has a global blast radius. An event that impairs the US-EAST-1 region can prevent critical administrative actions—including those necessary for disaster recovery, such as updating DNS records or creating emergency access roles—from being performed in any other region worldwide. This systemic risk, which has been a factor in multiple historical outages, is not sufficiently mitigated or transparently communicated to customers, leading to architectural assumptions that do not align with the operational reality of the platform.
5.2 Finding 2: The Inevitability of Cascading Failures in Tightly-Coupled Systems
The deep and often opaque inter-dependencies between foundational AWS services create an environment where localized faults inevitably cascade into widespread, multi-service outages. The failure of a single core component, such as the DynamoDB endpoint resolution system in this incident, can trigger a domino effect that propagates through the service stack to impact compute, identity, monitoring, and application services. The "blast radius" of such events is consistently larger than anticipated because the full dependency graph of the ecosystem is too complex to be fully understood or modeled. This tight coupling makes the system fragile, where the failure of one part leads to the failure of the whole.
5.3 Finding 3: Insufficient Isolation of Monitoring and Remediation Tooling
Critical incident response infrastructure, including the AWS Service Health Dashboard and customer support systems, lacks sufficient fault isolation from the production environment it is intended to monitor. These "meta-services" are built on the same core AWS primitives and are often dependent on the same foundational services in US-EAST-1 that are the source of major outages. This creates a circular dependency that results in a loss of visibility and control during the most severe incidents, hampering diagnostic efforts, delaying recovery, and preventing clear communication with customers. This is a recurring, unresolved vulnerability in AWS's operational posture.
5.4 Recommendations for Architects and Operators: Principles of Static Stability and Fault Isolation
To build applications that can survive this class of failure, architects and operators must move beyond a simple multi-Availability Zone strategy and adopt more rigorous resilience patterns.
- Embrace Multi-Region Architectures: For any critical workload, a single-region deployment is an inadequate defense against systemic failures originating in
US-EAST-1. Workloads must be designed with either an active-active or active-standby posture across at least two geographically distinct AWS regions. This is the only effective way to isolate a workload from a full regional failure. - Design for Static Stability: A core principle of resilient design is to avoid dependencies on control planes during a failure event. Recovery mechanisms should not rely on the ability to launch new instances, update DNS records via API, or create new IAM roles. Instead, systems should be "statically stable," meaning they can recover without making any control plane calls. This involves pre-provisioning sufficient capacity in the standby region and using data plane mechanisms—such as
Route 53health checks routing traffic away from an unhealthy endpoint—to orchestrate the failover automatically. - Decouple and Isolate Dependencies: Conduct rigorous dependency analysis to identify and minimize any hard dependencies on services homed in
US-EAST-1, particularly within the critical recovery path. Implement architectural patterns that promote loose coupling and graceful degradation. This includes usingcircuit breakersto stop requests to a failing dependency and prevent cascading failures, andqueue-based load levelingto buffer requests and decouple components, allowing parts of the system to function even when others are down. - Implement Independent, External Monitoring: Do not rely solely on the cloud provider's status page or internal monitoring tools as the single source of truth during an outage. Employ external, third-party monitoring and observability platforms that have a diverse, multi-provider footprint. These tools are not subject to the same fate-sharing as the provider's native tools and can provide an independent, external view of service health, which is critical for timely detection and accurate diagnosis.
5.5 Recommendations for Industry and Policymakers: Addressing Systemic Cloud Concentration Risk
The October 20th outage is a stark reminder of the systemic risk created by the concentration of the world's digital infrastructure in the hands of a few hyperscale cloud providers.
- Promote Architectural Transparency: Cloud providers must provide clearer, more explicit, and more accessible documentation regarding cross-region dependencies and the specific failure domains of their global service control planes. Customers cannot be expected to build resilient systems without a transparent and accurate understanding of the underlying platform's failure modes.
- Invest in Multi-Cloud and Hybrid Resiliency: For services deemed critical to national security, economic stability, or public safety, reliance on a single cloud provider—and particularly a single region within that provider—constitutes an unacceptable concentration of risk. Policymakers and operators of critical infrastructure should view investment in robust multi-cloud and hybrid cloud architectures as a strategic imperative for national digital resilience.
- Maintain and Standardize Post-Mortem Reporting: The practice of publishing detailed, technically transparent Post-Event Summaries (PES) after major incidents is invaluable for the entire industry. AWS has historically provided such reports, and this practice must be maintained and encouraged across all major providers. The industry should work toward a standardized format for these reports that mandates the disclosure of not just the proximate cause but also the full chain of cascading service dependencies revealed during an incident, to facilitate collective learning and improvement.
Conclusion
The Amazon Web Services outage of October 20, 2025, was a watershed moment for the cloud computing industry. It served as a powerful demonstration that despite immense investments in redundancy and engineering, the complex, tightly-coupled nature of modern hyperscale platforms creates the potential for rapid, cascading failures with global consequences.
This analysis has established that the outage was not a freak accident or an unforeseeable event. It was the predictable outcome of accumulated architectural debt, systemic concentration risk in the US-EAST-1 region, and the inherent fragility of deeply interconnected distributed systems. The failure chain—from a specialized DNS resolution issue with a core database service to a worldwide disruption of the digital economy—followed a pattern seen in previous major AWS incidents. This recurrence indicates that the underlying systemic vulnerabilities have not been fully addressed.
The key lessons from this event are clear. For architects and engineers, resilience can no longer be an afterthought; it must be a primary design consideration. Principles of static stability, aggressive fault isolation, and the deliberate decoupling from single points of failure like the US-EAST-1 control planes are not theoretical ideals but practical necessities for building survivable systems. For the industry and for policymakers, the outage is a stark warning about the dangers of infrastructure monoculture. The concentration of critical digital services on a small number of platforms, and within specific regions of those platforms, creates a systemic risk that demands strategic diversification.
Moving forward, the paradigm of resilience engineering must evolve. It must account for the complex, emergent behaviors of systems at scale and assume that failure is not a matter of if, but when. By learning from the clear and repeated lessons of this and prior outages, the technology community can begin to build a more robust, transparent, and genuinely resilient digital future.